




Pattern Redundancy Analysis for Document Image Indexation & Transcription IntroductionOur project is part of a greater research project which we have been working on for 10 years, and which is currently being carried out in a program of regional development of old books (dating mainly from the Renaissance), i.e. the “Virtual Humanist Libraries” controlled by the Center for Graduate Studies of the Renaissance - CESR (http://www.bvh.univ-tours.fr/). To turn these ancient books into accessible digital libraries, we are developing image-processing software which participates in a full processing chain, including layout analysis, text/graphics separation, Optical Character Recognition (OCR) and text transcription. The proposed research project is focusing on these last two steps of the process. The standard OCR techniques can not be successfully applied to old or “noisy” documents due to high levels of degradation. This is why our research project focuses on alternative techniques to traditional OCR to provide indexation of images and text transcription. The originality of our work relies upon the analysis and exploitation of pattern redundancy in documents to allow efficient and quick transcription of books as well as identification of typographic materials. This pattern redundancy is mainly obtained via clustering methods. Like this, the traditional OCR problem could be reformulated into a text transcription one. What is clustering and why is it so important for character processing?Clustering is the assignment of a set of objects into subsets (called clusters) so that objects in a same cluster are considered as similar in some sense. The design of such algorithms is a complex task, relying on different approaches including hierarchical, partitional, sub-space clustering, etc. In addition, clustering problems can be defined as supervised or unsupervised, and the number of clusters to be produced may or may not be known before the process is begun. Clustering algorithms may be applied for character recognition, to reformulate the traditional OCR problem into a text transcription one. A text, be it ancient or not, is made up of sequences of symbols. The scanning process produces pictures where symbols are represented as thumbnails of patterns (a pattern could be a single character, a part of a character or a set of joined characters), which may be more or less distinct (see Figure 1). Without prior knowledge about the meaning of these symbols, the application of a clustering approach assigns thumbnails of a similar shape to the same cluster. As an example, one cluster containing thumbnails of the lowercase letter “a,” another one the uppercase letter “A,” yet another one the letter “b” in a specific font, and so on. Two main features have to be considered to design such a clustering algorithm:
Once the clustering is done, a user could assign a label to each cluster using a Graphics User Interface (GUI). These labels are then automatically assigned to each pattern, thus achieving the text transcription of the whole book. In this way, if 90% of patterns are detected as redundant, only one character in ten will be labeled by the user in order to transcribe the book. The application of clustering techniques to the processing of characters in old books was initially introduced in the framework of the DEBORA project (http://www.comp.lancs.ac.uk/computing/research/cseg/projects/debora/). The primary goal of this project was to employ clustering techniques to detecting redundant patterns in a book in order to compress the image data for storage purposes. The LI laboratory was the first to extend this approach to text transcription, through the development of the AGORA software as explained below. We note that this approach today constitutes one of the main axes of the IMPACT project (http://www.impact-project.eu/), funded under the seventh Framework Program of the European Commission, to improve OCR technologies in the context of mass digitization. 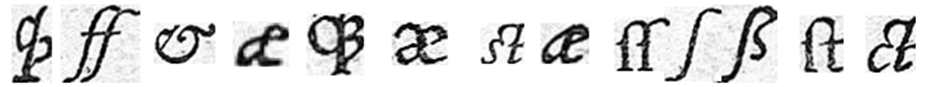 Figure 1: Samples of single and ligatured characters found in ancient documents
|
| Number of pages | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| Total # of clusters of binary patterns | 555 | 915 | 1,209 | 1,485 | 1,678 | 1,870 | 2,083 | 2,262 |
| Total # of characters | 2,327 | 4,245 | 6,681 | 8,681 | 11,159 | 13,599 | 16,141 | 18,028 |
| Redundancy rate | 76% | 78% | 81% | 82% | 84% | 86% | 87% | 88% |
Table 1: Evolution of the patterns redundancy rate in an ancient document part
These results support our choice to improve our pattern extraction and analysis process, and to build up character pattern dictionaries for entire books.
We propose to use the Google award to expand our approach and to bring about new, interesting results by:
- reducing the number of patterns to be recognized by OCR (OCRopus or another commercial OCR software) and thus shorten the processing time.
- simplifying the interactive or collaborative transcription (keyboarding) by reducing the number of patterns that require manual tagging (for characters which are not processed or are incorrectly processed by OCRs)
- improving the lexical and syntactical corrections following the recognition process by combining pattern redundancy analysis and language models to perform automatic correction of OCR results
- identifying typographical families of characters (e.g. mono-font systems) to set up OCR. The identified typographical families will be used as metadata by OCRs to improve the recognition rates.
These points are detailed below.
Pattern redundancy for text recognition or collaborative transcription using RETRO
In this proposal, we are introducing a new alternative method to OCR for accessing a text: Computer Assisted Transcription. We have already designed a prototype software called RETRO, which allows semi- automatic transcription of the text parts previously processed by AGORA (see Figure 2).
RETRO works from characters clusters created by AGORA to transcribe the textual parts of a book with little effort, using an interactive labeling approach of frequent patterns with a user. RETRO allows us to quickly label 80% of characters in a book without requiring a huge time investment for a user (experiments show an average time of less than two hours). Moreover, this transcription method allows us to easily deal with special characters which appear frequently in old books (see Figure 3). For example, most of the European fonts before the 19th century use the ligature “ct” (concatenation of a “c” and a “t”, see Figure 1, last item). As this double character cannot easily be split into two characters by standard OCRs, they are often improperly identified. Thanks to our method, such ligature-based patterns can be transcribed into character couples without any modification of the recognition process. This is the same problem for “long s” characters (unicode U017F) that are often confused with the letter “f” by OCRs (see Figure 1, item #10).
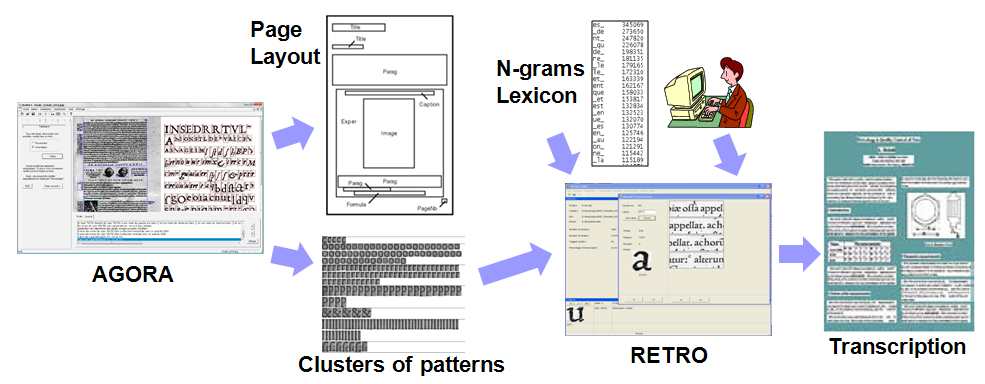
Figure 2: AGORA and RETRO
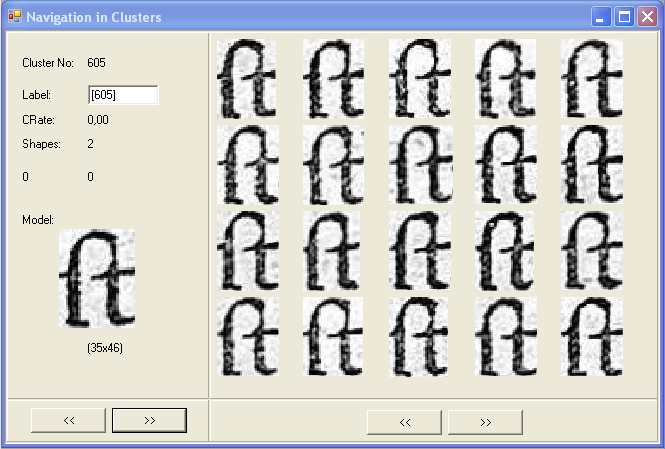
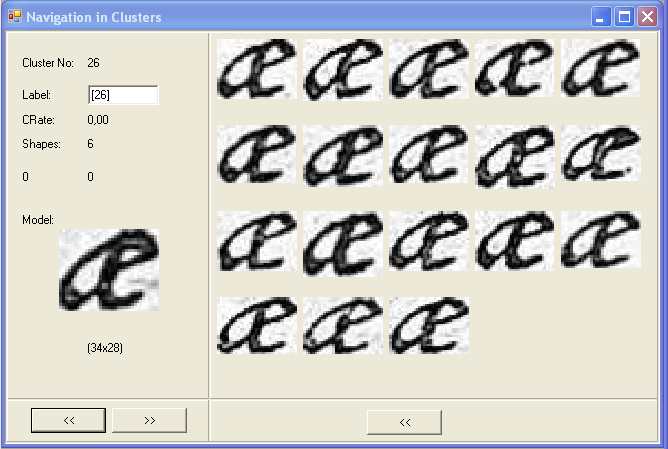
Figure 3: The navigation tool (RETRO) which show two examples of ligatured characters groupes into two clusters
In order to illustrate the abilities of our approach software, here are some results obtained with our software from
a complete book of 150 pages (De Humani Corporis Fabrica by Andreas VESALIUS, 1543):
- 1,062,081 patterns extracted
- 40,000 clusters created by AGORA
- 90% of these clusters are composed of less than 10 occurrences of the pattern
- ignoring these clusters during transcription means missing one character in 14 (more than one per line of text)
- 57% of clusters are composed of a single element
- the 200 largest clusters correspond to 85% of the text
To date, RETRO is still in development and could be improved in several ways:
- Coupling RETRO with the results of an OCR (such as OCRopus) will allow us to speed up the labeling process of clusters, OCRs will be used to automatically label the patterns, user interaction will then be limited to a visual inspection to detecting (and correcting) the incorrect OCR assignments.
- Improving the quality of the clustering process will probably solve most of the problems listed before (i.e in the experiment of the Vesalius book). The scientific literature proves that robust descriptors exist (e.g. Zernike coefficients, Fourier moments, etc.), and they could be employed within a clustering process to increase efficiency (i.e. to produce fewer and more homogeneous clusters). Post-processing could also be applied in order to correct the erronously assigned clusters (through merging and/or splitting processes).
We have already experimented some merging techniques based on the KARHUNEN-LOEVE distance between patterns. The representation of the eigenvectors clearly shows high similarities between combinations of merged patterns with patterns assigned in one shot (i.e. a correctly assigned cluster). The goal is now to design an unsupervised criteria to define an aggregation operator. - The use of linguistic knowledge (lexicons, statistics about proximities between letters, etc.) will probably significantly increase the quality of results. We propose to look for statistical language models in our system (e.g. n-gram). These statistical language models are restricted to characters, but can be extended to words by incorporating appropriate lexicons. Corpora for designing such models, and for learning about other probabilities, are available at the CESR.
- Adding contextual visualization (i.e. browsing between pattern instances inside a book, to see the instances of patterns in words or sentences) will certainly help the user in the task of assignment. In addition, extending the interface to collaborative transcription (with annotation) will help in solving the ambiguous and harder assignment cases.

Figure 4: (left) Interactive transcription with RETRO; (right) RETRO interface for manual transcription
Pattern redundancy for Font analysis (recognition and production)
It is also possible to use our clustering approach to extract and create new font packages from specific printing material (e.g. rare books printed with particular plug sets). These new font packages could be incorporated during the training step of Optical Fonts Recognition (OFR) methods, in order to improve the recognition results of OCRs on rare or specific books. Indeed, OFRs are generally restricted to popular fonts. Specific or rare fonts are usually not taken into account, which results in a high level of error during standard OCR. Our approach could help in designing new font packages, to support standard OFR methods and then improve the results of OCRs. This work is done in collaboration with specialists in typography of the Renaissance period (CESR).
We propose to create a general classification of all Early Modern fonts and character styles by using information from pattern redundancies studied in the previous stage. As several characters found in a printed document may share the same pattern (as part of the same cluster), our method consists of establishing the relationship between words containing characters which have the same binary patterns. In other words, two different words are put in the same typographical family if they share at least one binary pattern of a character. This relationship creates a new set of words which have characters printed with the same style; the construction of this set is achieved iteratively by the following algorithm. The results of this method show that words printed in a different style, size, or font cannot be found in the same family. However, different families computed by our approach can actually represent a single typographical class.
If the newly created families are sorted by decreasing order of corresponding words, we automatically find the main typography class as well as minor typographies used occasionally for a precise logical meaning. Very small typographical families represent words which seldom occur in the text (text in graphics, titles, authors' names, etc.). This analysis could provide very interesting information for automatic indexation of some parts of book. This information could be added in a database, or encoded in a XML-TEI file, and used by researchers working on linguistic or literary issues.
The identification of typographic materials could also allow for the study of both aesthetic aspects of printing (the thickness and the shape of printing types evolved greatly from the 15th to the mid-16th century) and economic aspects of printing: until the second half of the 16th century, printing types circulated among workshops, and printers frequently sold or lent types to their fellows. Studying the circulation of printing tools and materials could reveal new aspects of the book trade in the Renaissance. On the other hand, beginning in the 17th century, the trade of printing materials was dominated by a few important foundries in Antwerp, Frankfurt or Paris: identification of fonts used in the 17th or 18th centuries could reveal the influence of each of these foundries in Europe until the “graphic revolution” in the late 18th century (with Baskerville, Bodoni, Fournier, and then Didot).
Pattern redundancy for improving the OCR learning step (dataset production, model selection)
Thanks to the identification of specific fonts inside images, it is possible to automatically select a specific OCR dedicated to that font (mono-font OCR). This will increase the potential performances of OCR systems or of the RETRO transcription method presented above.
Moreover, our experiments in modifying the learning set of the OCR according to fonts present in documents have demonstrated significant improvement on synthetic data: table 2 shows the differences between a poly-font OCR system learned over 70 fonts, its adapted version incorporating a few character samples of the font, and the mono-font OCR learned using only samples of the given font. For old books (17-18th century), replacing the default learning set by template characters from Human or Garalde font families (like Jenson or Garamond of Adobe) has resulted in a large improvement of the OCR results. These fonts include numerous ligatures between characters and also special characters used during the Renaissance period. We have also been able to use the “GaramonGilQuatre” font drawn by Pierre AQUILON from CESR in order to simulate the font used in Incunable books.
Consequently, using AGORA and RETRO, it also becomes possible to construct new learning sets or new fonts from characters (binary patterns) which are directly extracted from the clusters of characters coming from specific documents or books. The newly obtained fonts have significant differences compared to currently existing fonts. For example, the thickness of actual Truetype fonts is smaller than those of the Renaissance period due to the paper and ink that was used.
| Font | poly-font system | adapted poly-font system | mono-font system |
| Average (30 fonts) | 86.59 | 96.06 | 99.55 |
| Berkeley Old | 96.62 | 97.2 | 98.98 |
| Banco | 34.08 | 73.46 | 98.77 |
| Mistral | 46.63 | 92.16 | 94.89 |
| Fette Kanzlei | 68.36 | 95.74 | 99.43 |
Research and Development: goals of the project
If we obtain Google award, we will:
- Create an open-source forge for RETRO and AGORA in order to make the following improvements
- Experiment with coupling RETRO with OCRopus to check the recognition of the OCR by visual inspection, to correct and complete the results through semi-manual transcription.
- Improve the clustering method (pattern redundancy analysis) by using better similarity measures than pattern matching and by using better features than pixels. Post-processing achieved via the obtained clusters (merging or splitting of certain clusters, threshold selection) is also conceivable.
- Add some linguistic knowledge (lexicons, statistics about proximities between letters, etc.) to increase the quality of the result. We propose to investigate the integration of a statistical language model (like ngram) into our interactive transcription system.
- Improve the user interface to facilitate transcription or to allow collaborative transcription (with annotation).
- Add new functionalities to RETRO concerning typographical studies: the creation of typographical families can be used to generate learning datasets that can be used by OCRopus or RETRO.